“Facebook would never change their advertsing relying on a sample size as small as we do medical research on.”
(David Wilbanks)
People want to learn about themselves and get their lives soundly supported by data. Parents record the height of their children. When we feel ill, we measure our temperature. And many people own a bathroom scales. But without context, data is little meaningful. Thus we try to compare owr measurements with those of other people.
Data that we track just for us alone
Self-tracking has been trending for years. Fitness tracker like Fitbit count our steps, training apps like Runtustic deliver to us analysis and benchmark us with others. Since 2008, a movement has been around that has put self-tracking into its center: The Quantified Self.

Self-tracking has been tending for years. In this picture you see a wristband that already made it into a museum and is now on display in the London Science Museum.
However it is not just self-optimizer and fitness junkies who measure themselves. Essential drive to self-tracking originated from self-caring chronically ill.
Data for the physician, for family members, and for nursing staff
In the US like in many countries lacking strong public health-care, it becomes increasingly common to bring self-measured data to the physician. With many examinations this saves significant consts and speeds up the treatment. With Quantified Self, many people have been able to get good laboratory analytics about their health for the first time ever. One example is kits for blood analysis that sends the measurement via mobile to the lab and then displays the results. Such kits are e.g. widely in use in India.
Also for family members and nursing staff, self-tracked data of the pations is useful. They draw a realistic picture of our conditions to those who care for us. Even automatic emergency calls based on data measured at site are possible today.
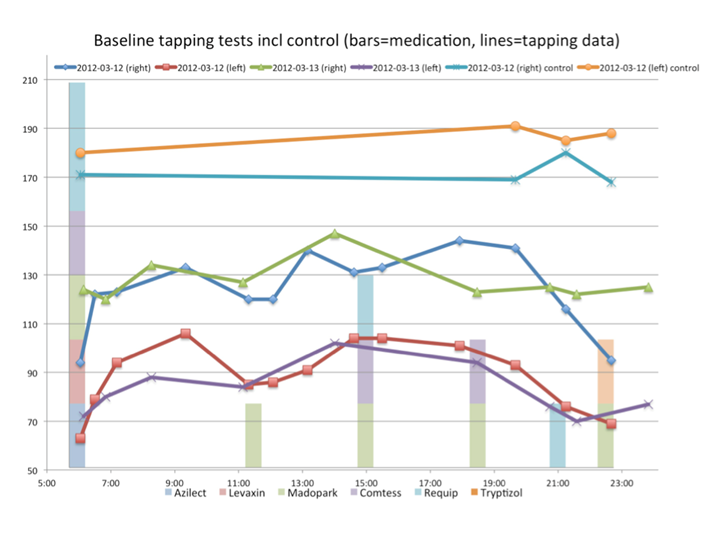
The image at the top is taken from the blog of Sara Riggere, who suffers from Parkinson. Sara tracks her medication and the syptoms of her Parkinson’s desease with her smartphone. Her story is worth reading in any case, and it shows all facettes that make the topic “own data” so fascinating:
http://www.riggare.se/ and
http://quantifiedself.com
Mood-tracking – a mood diary. People suffering from bipolar disorder try to help themselves by recording their mood and other influences of their lives. By doing so, they are able to counteract, when they approach a depression, and they are able to finetune their medication much better, than it would be possible by the rare visits to their psychiatrist. (Shown here is soundfeelings.com)
Data for research
Self-recorded data for the first time maps people’s actions and condition into an uninterupted image. For research, these data are significantly richer than the snap-shots made by classic clinical research – regarding case numbers as well as by making possible for the first time to include the multivariate influences of all kinds of behavior and environment. Even if only a small fraction of self-trackers is willing to share their data with researchers, it is hardly to imagine the huge value the findings will have for medicine, enabled by this.
Privacy
The difficulty with these data: they are so rich and so personal, that it is always possible to get down on the single individual. Anonymization, e.g. by deleting the user id or the IP adress is not possible. Like fingerprints, the trace we leave in the data can always identify us. This problem cannot be solved by even more privacy regulation. Already today, the mandatory committment to informed consent and to data avoidance impede research with medical data to such extent, it is hardly worthwhile to work with it, at all. The only remedy would be comprehensive legal protection. Every person sharing their data with research has to be sure that no disadvantages will come from their cooperation. Insurance companies and employers must not take advantage from the openness of people. This could be shaped similar to anti-discrimination laws. Today, e.g. insurance companies are not allowed to differenciate their rates by the insurant’s gender.
Algorithm ethics
Another issue lies within the data itself. First, arbitrary, technical differences like hardware defects, compression algorithms, or samling rates make the data hard to match. Second, it is hardly the raw data itself, but rather mathematical abstractions derived from the data, that gets further processed. Fitbit or Jawbone UP don’t store the three-dimensional measurements of the gyroscope, but the steps, calculated from it. However, what would be regarded as a step, and what would be another kind of movement, is an arbitrary decision of the author of the algorithm programmed for this task. Here it is important to open the black boxes of the algorithms. As the EU commission demands Google to open its search algorithms, because they suspect (probably with good reasons) that Google would discriminate against obnoxious content in a clandistine way, we have to demand to see behind the tracking-devices from their makers.
Data is generated by the users. The users have to be heared what is made from it.