
This is the third article in a series of technical posts about how Track & Trust works at a component level. The world today is full of fake news and dubious “facts.” Consequently, we face a significant challenge in verifying the accuracy of the data we receive. Moreover, a major part of this challenge is identifying the source of this data. We can’t predict who the end users of the Track & Trust system will be or exactly what they will want to communicate, which makes this task even more difficult. To address this issue, we must ensure that data entering our system are valid. This post explores how the “Trust” part of Track & Trust works. It explains exactly how we maintain the chain of data authenticity.
Quick navigation links to the follow-up articles will be provided at the bottom of each article once the series is complete. For now, let’s jump in.
Establishing a foundation for the data authenticity chain
We designed our system to accommodate key requirements that establish a foundation for data authenticity. Specifically, our goal was to create a flexible system. This system can work with any logistics company, regardless of their internal processes. Notably, we achieved this flexibility, which is a key benefit of Track and Trust. This allows us to collaborate with a wide range of partners. Furthermore, logistics companies can increase the number of data points they receive about their shipments from the field by using Track & Trust.
This, in turn, enables them to achieve probabilistic 360° supply chain tracking. Our team structured the Track & Trust data to integrate easily into any logistics database. In particular, we use a series of linked cryptographic signatures and blockchain transactions to create this data authenticity chain. Finally, this chain of custody has a specific purpose. It ensures that we can authenticate and validate offline events once they reach our servers.
How does the data authenticity chain work?
TLDR: We leverage APIs to take inputs from our customers (Logistics Firms) as well as to give them valuable probabilistic 360° supply chain tracking data back. For demonstration purposes we have built a front-end website to make the system tangible but the magic happens via our swagger API.
The processes surrounding our data authenticity chain are pretty technical. To make it easier to understand we’ve formated the workflow into a sequence diagram that anyone can understand.
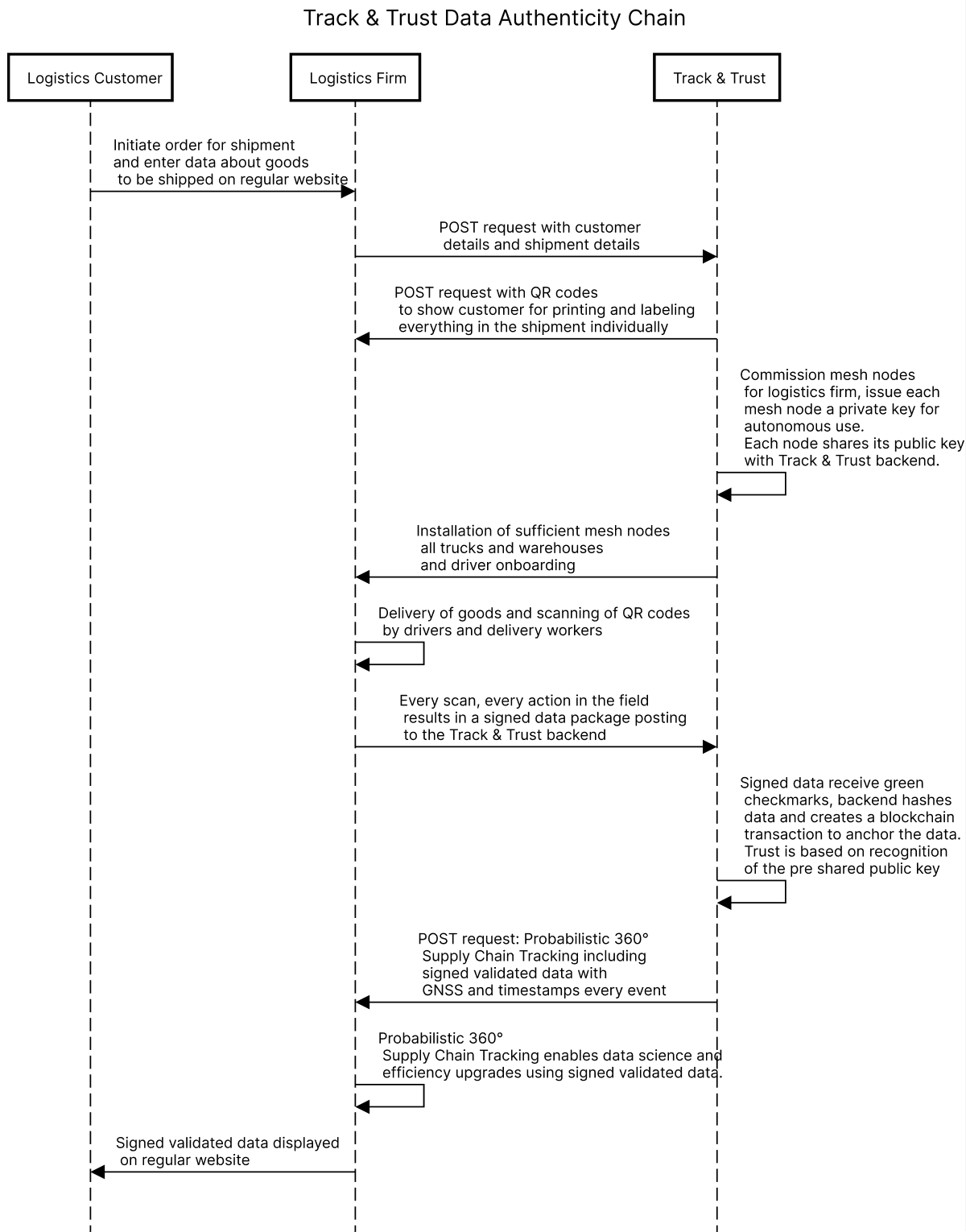
In summary, our data authenticity chain is simply a way of validating, recording and making messy data from the field trustworthy. Once that’s accomplished leverage our blockchain toolkit to make those data immutable and highly tamper resistant. It’s a chain of custody for that data that includes built-in proof of origin. This, in turn, enables traceability and trust beyond the current state of the art.
Our next post will cover all of the ways that we can view this information. We’ll also be covering the orchestration systems operating in the background that enable us to do over the air updates to the hardware. There will be dashboards, monitoring and CI/CD galore for your perusal.