
by Admin | 30 March 2026 | Blockchain
At Datarella, we specialize in building secure, production-ready AI agents and decentralized systems. Our work with RAAY RE – the AI operating system for real estate developers, asset managers, and funds – applies these capabilities directly to property management. Here’s a technical breakdown of how agentic AI transforms operations, with emphasis on architecture, data handling, and system integration.
What Agentic AI Really Means Technically
Traditional AI in real estate typically stops at analytics dashboards or chat-based query answering. Agentic AI goes further: agents are goal-directed autonomous systems that perceive their environment (via data streams and APIs), reason over multiple steps, plan action sequences, interact with external tools and services, and execute tasks end-to-end while maintaining state and handling exceptions.
In practice, these agents use:
- Orchestration frameworks such as LangGraph for building bounded, controllable multi-agent workflows.
- Tool-calling and function execution to interface with databases, property management software, accounting platforms, IoT gateways, and third-party APIs.
- Memory and state management to track long-running processes (e.g., a maintenance ticket from detection to closure).
- Planning and reasoning loops (often powered by large language models combined with rule-based safeguards) to break down high-level goals into executable sub-tasks.
The result is systems that don’t just suggest actions – they carry them out reliably within defined guardrails.
Core Technical Capabilities in RAAY RE
RAAY RE’s Workflow module deploys AI-driven agents that operate across fragmented, decentralized data landscapes typical in property portfolios. Here’s how the technology addresses real challenges:
- Decentralized Data Synchronization
Property data rarely lives in a single monolithic database. Agents autonomously query and reconcile information from multiple sources — PMS platforms, ERP/accounting systems, IoT sensor networks, external credit bureaus, and document repositories. They perform real-time integrity checks, detect anomalies or conflicts, and orchestrate secure updates while preserving audit trails. This reduces manual reconciliation errors and supports GDPR-compliant data flows through controlled access and logging.
- Multi-Step Workflow Automation
Agents handle complex, conditional processes by chaining actions: perceive → reason → act → verify → iterate. Examples include:
- Maintenance Operations: Ingest IoT sensor readings and image data → apply predictive models for anomaly detection → evaluate repair options against budget rules and vendor SLAs → dispatch approved contractors via API → monitor progress through status updates → confirm completion and trigger invoice validation.
- Financial Processes: Automate rent collection reminders with probabilistic dunning (adjusting based on payment likelihood models), perform transaction matching across bank feeds and ledgers, flag discrepancies, and generate compliance-ready reports.
- Document Intelligence: Use extraction models to pull structured data from unstructured leases, inspection reports, and invoices → abstract key clauses and obligations → populate downstream systems → enforce regulatory checks.
- Tenant-Facing and Leasing Agents
24/7 communication agents integrate with chat, email, and voice channels to handle routine inquiries, schedule viewings, and route escalations. Leasing agents combine multi-source data (credit history, behavioral signals, references) to evaluate applicants and score risk, accelerating approvals while maintaining explainability for compliance.
Security and Reliability Engineering
Datarella places strong emphasis on making agents enterprise-ready:
- Bounded agent orchestration (using patterns like LangGraph and Inngest) to prevent uncontrolled autonomy and keep agents within predefined scopes.
- Autonomous agent hardening and isolation — including threat modeling, MCP server security, API security layers, and multi-agent interaction safeguards.
- Compliance-by-design features for data protection regulations, with transparent logging and human-in-the-loop options for sensitive decisions.
- Web3 foundations where appropriate: leveraging blockchain for immutable audit trails, decentralized identity elements, or secure data marketplaces in multi-stakeholder scenarios (building on our experience with Fetch.ai and similar decentralized agent systems).
These measures ensure agents remain controllable, auditable, and resilient even when operating across distributed environments.
Technical Benefits and Scalability Considerations
From an engineering standpoint, agentic systems deliver:
- Reduced operational latency through parallel tool use and automated decision loops.
- Lower error rates via consistent execution paths and automated verification steps.
- Improved scalability: portfolios can grow without linear increases in administrative staff, as agents handle volume spikes in inquiries, maintenance tickets, or reporting cycles.
- Better data quality through continuous synchronization and anomaly detection across heterogeneous sources.
Integration typically involves secure API layers, event-driven architectures, and gradual rollout — starting with bounded pilots on specific workflows before expanding to full AI-native operations.
Looking Ahead: Toward Fully AI-Native Real Estate Operations
Agentic AI in property management is still evolving. Future iterations will likely incorporate more advanced multi-agent collaboration (where specialized agents negotiate or hand off subtasks), tighter integration with edge/IoT devices, and enhanced reasoning capabilities for strategic forecasting.
At Datarella, our focus remains on combining robust AI agent development with Web3 infrastructure and security-first design. Through RAAY RE, we help real estate organizations move from reactive, manual-heavy processes to proactive, autonomous systems that synchronize data intelligently and execute reliably at scale.
If you’re exploring agentic architectures for property management, whether for workflow automation, decentralized data orchestration, or secure multi-agent systems, we’d be happy to discuss the technical details.

by Michael Reuter | 21 August 2025 | Blockchain, Gaia-X, moveID, SSI
Decentralized systems have been in vogue at least since the rise of Web3, particularly in Europe. Unlike in the USA or China, where centralized structures prevail, Europe consists of many comparatively small democratic nations that must coordinate in all areas of life to provide their citizens with a high quality of life.
Similar to participants in decentralized Web3 networks, individual citizens in Europe enjoy a high degree of autonomy, freedom, and self-determination. While this autonomy is inherently embedded in the software code of Web3, in Europe, national governments create the legal frameworks. Examples like eIDAS and Self-sovereign Identities (SSI) establish EU-wide standards that enable secure cross-border digital transactions.
At Datarella, we have actively participated in decentralized systems through our projects, most recently in the GAIA-X funding project moveID. The experiences gained lead to two key conclusions: The values and benefits of decentralized systems are recognizable and measurable, offering flexibility and innovation in dynamic environments. However, decentralized systems are not feasible or value-creating without a direct connection to centralized elements. This may sound contradictory at first, but it is not.
The Necessity of Centralized Elements in Decentralized Systems
Decentralized systems do not develop from within themselves; they always require a central idea or organization as the initial spark. Furthermore, a central entity must permanently handle tasks in governance, administration, and management. Without this, decentralized systems tend toward apathy or inactivity, as current incentive models do not ensure long-term constructive activity. A decentralized system remains active only as long as central functions provide the necessary incentives. Additionally, basic infrastructure must be created and operated – a task typically handled centrally, with costs distributed among participants.
From the perspective of organization theory, this aligns with contingency theory: There is no universally best structure; the choice between central and decentralized depends on the environment. In stable contexts, centralized systems provide efficiency and control, while decentralized ones promote agility in volatile markets. Henry Mintzberg describes in his organizational models that centralized structures (e.g., Machine Bureaucracy) are suitable for standardization, whereas decentralized ones (e.g., Adhocracy) foster innovations. Disadvantages of centralized systems include the lack of flexibility, while decentralized systems can lead to coordination issues.
Symbiosis as the Path to Success
In short, decentralized and centralized systems can form a beneficial symbiosis that compensates for the drawbacks of monolithic approaches and generates more prosperity for all participants. Hybrid models, as recommended in organization theory, combine stability with agility and are exceptionally sensitive in complex environments.
A necessary prerequisite for this symbiotic interplay is the ability and willingness of participants to understand the advantages and limitations of each system, along with the commitment to contribute to governance constructively. Only then do the positive outcomes emerge. Participants who see only the benefits of a monolithic structure should be excluded to maintain integrity.
At Datarella, we apply these insights in our data-driven solutions for health and sustainability, developing hybrid systems that link autonomy with reliable governance.
Do you have experience with such structures? Please share them in the comments!

by Simon Zehentreiter | 12 June 2025 | AI, Autonomous Agents, Blockchain, Gaia-X, MOBIX, moveID, SSI
After three years of intense collaboration, innovation, and field testing, the moveID project—part of the Gaia‑X 4 Future Mobility initiative—has made significant strides toward redefining how mobility ecosystems work. At its core, moveID aimed to create a decentralized, user-centric infrastructure where vehicles, infrastructure, and service providers interact seamlessly using Self-sovereign Identity (SSI) and AI agents.

Building the Foundation for Trusted Machine Communication

Working alongside industry leaders such as Bosch, Airbus, Continental, and leading Web3 projects, we contributed to building the technical and conceptual foundation for trusted machine-to-machine communication in the mobility sector. This included the secure exchange of credentials, decentralized data marketplaces, and AI-powered autonomous service interactions—all compliant with European data and privacy standards.
Demonstrating Real-World Impact: MOBIX Park & Charge
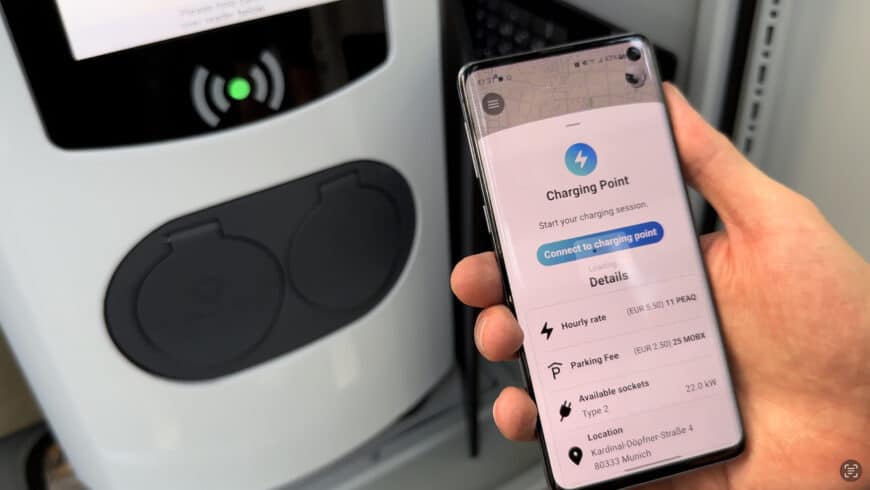
A standout achievement was the development and public demonstration of MOBIX Park & Charge, a fully operational system enabling electric vehicles (EV) to autonomously find parking spots, access charging stations, and handle payments. First showcased at IAA Mobility 2023, the system integrated SSI, blockchain-based payments, and AI agents in a live, real-world environment.
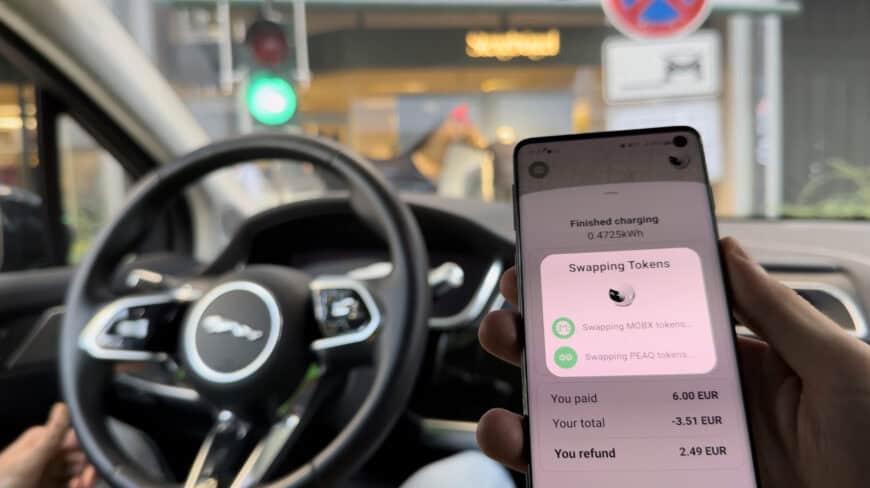
Scaling Toward Smart Cities
Beyond the demo, MOBIX has evolved into a scalable smart-city solution. By turning private EV chargers and parking spots into publicly accessible assets, we’re addressing key challenges in urban congestion and infrastructure scalability, while opening up new economic opportunities for individuals and municipalities.
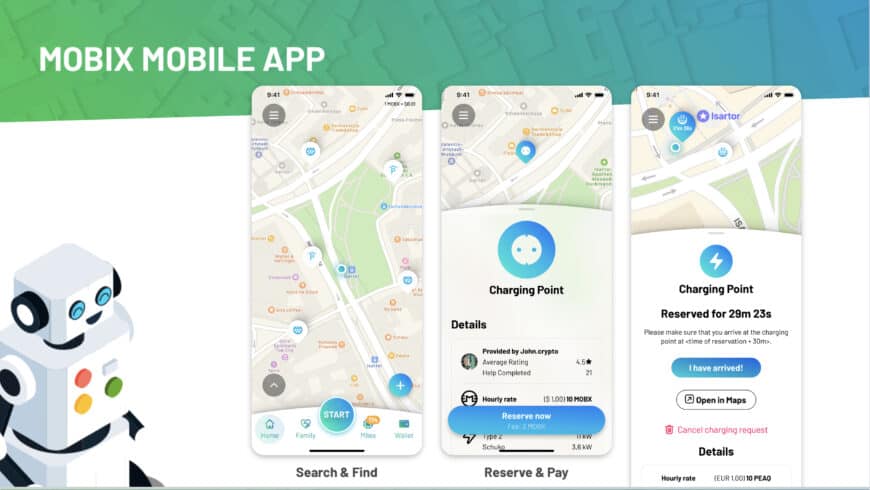
Where Web3 Meets AI
The project also served as a powerful example of the convergence between AI and Web3. By combining intelligent agents with decentralized infrastructure, we demonstrated how machines can not only interact but also negotiate, transact, and self-optimize—laying the groundwork for more ethical and transparent digital ecosystems.
A Foundation for the Future
In sum, moveID wasn’t just about mobility. It showcased how decentralized identity, autonomous agents, and AI can reshape how devices, services, and users interact—not just in cities, but across industries. As the project concludes, its outcomes provide a strong foundation for future applications in smart infrastructure, data sovereignty, and the broader digital economy.

by Simon Zehentreiter | 25 April 2025 | AI, Blockchain, COSMIC-X
In part two of the Cosmic-X blogpost series, we explained how we use the Secret Network blockchain and a custom Wallet Service to ensure the integrity and privacy of machine-generated data in Industry 4.0 environments. In this final part, we’ll show how we integrated the Wallet Service with live machines from SW and an AI service from inovex. Together, they power a proof-of-concept demonstrator for secure and accurate anomaly detection in machine components.
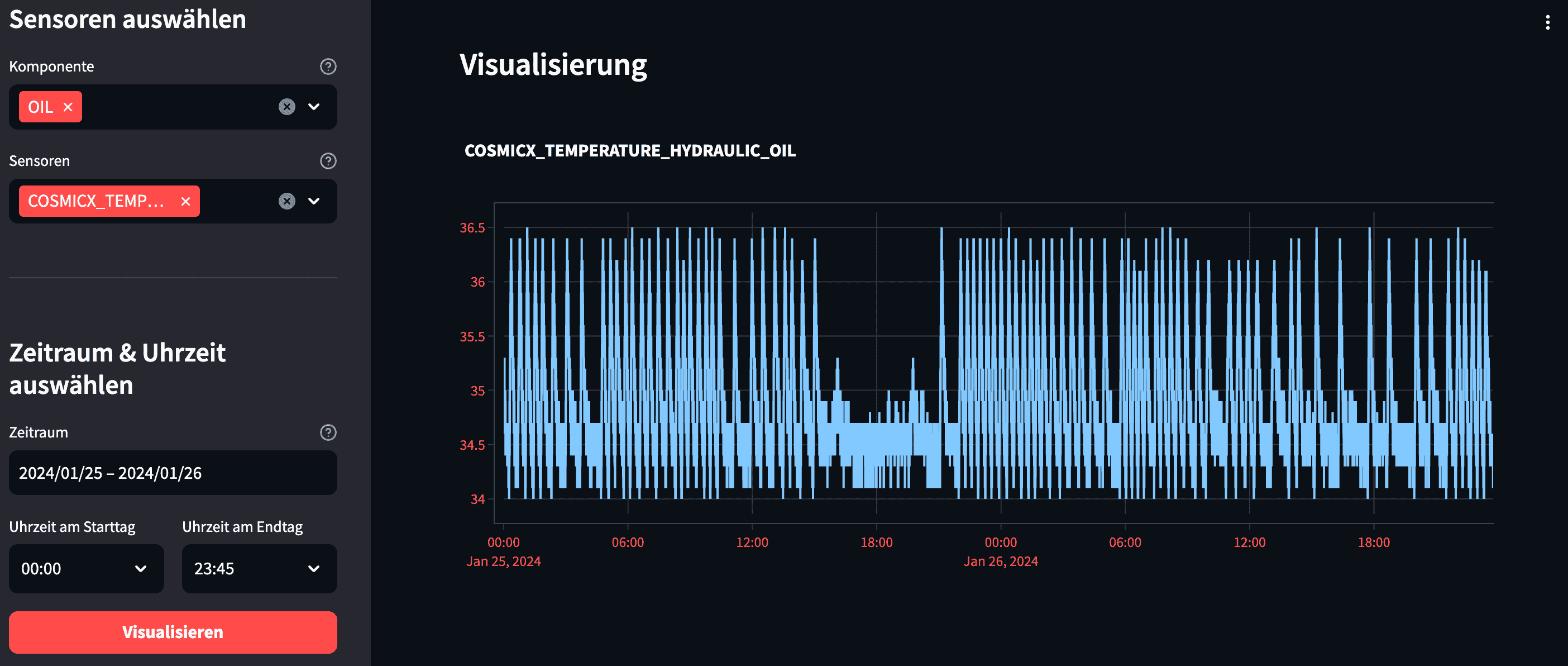
Visualizing Sensor Data
The demonstrator has three core features. First, the data exploration tool lets you visualize sensor data from three different machines. For granularity, you can filter by machine, component, sensor, and the timeframe you want to monitor.
Verification & Anomaly Detection
Next, the anomaly detection feature, coupled with data integrity verification. Like before, you can filter by machine, component, sensor, and timeframe. Additionally, you choose from three anomaly detection algorithms—Local Outlier Factor (LOF), DBSCAN, and Isolation Forest—and adjust their hyperparameters. After that, once you lock in your configuration and submit the query, the system fetches data from a central time series database. It then converts the data into the standardized format described in our previous post.
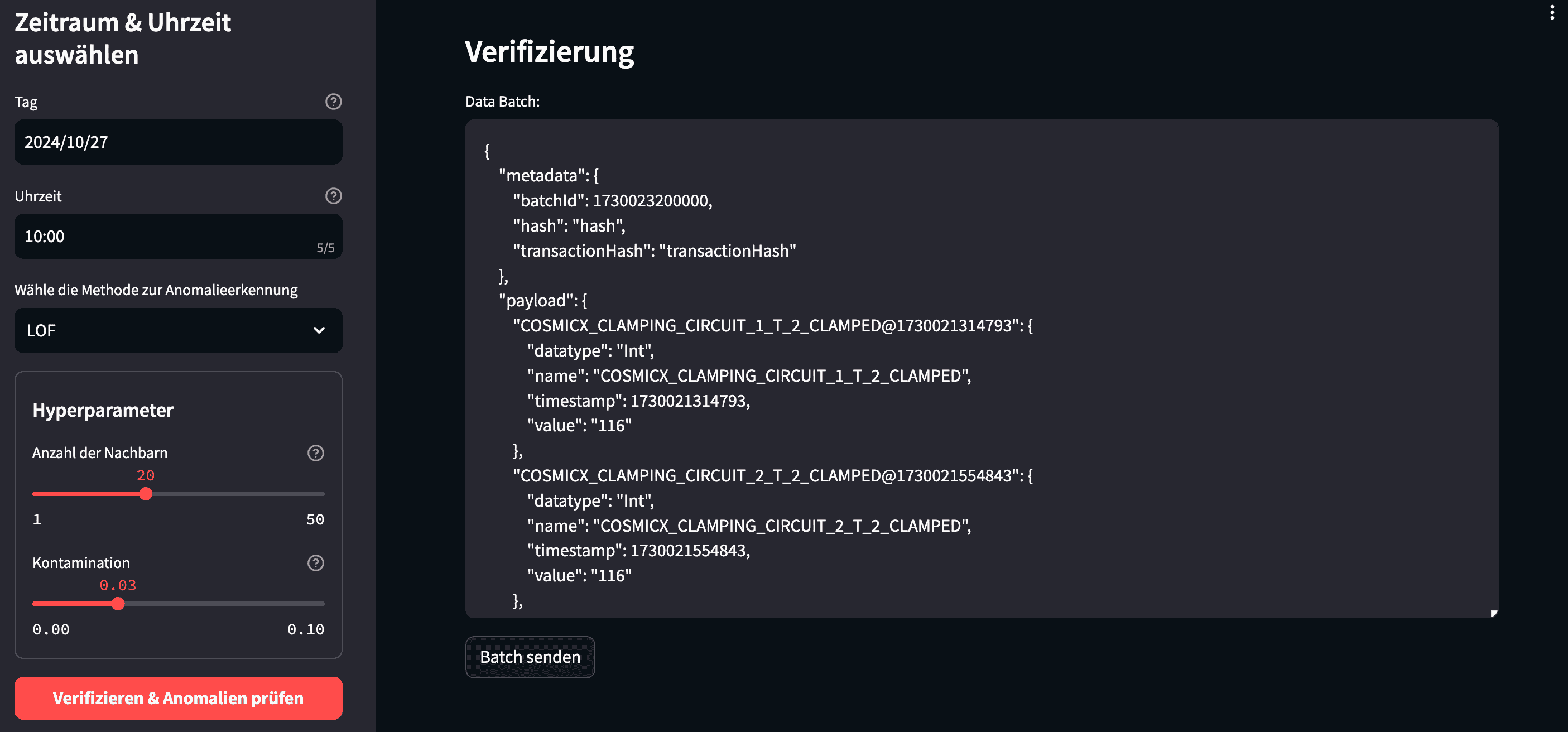
To ensure trust, the Wallet Service verifies the dataset by comparing a freshly generated fingerprint to the one anchored on the blockchain. It uses the standardized batchID for this lookup. If the fingerprints match, the AI service proceeds with the anomaly detection. Whenever the number of anomalies exceeds a defined threshold, the system flags the component as worn out. Consequently, it submits an automatic spare part order to the ERP systems of the manufacturer and the customer.
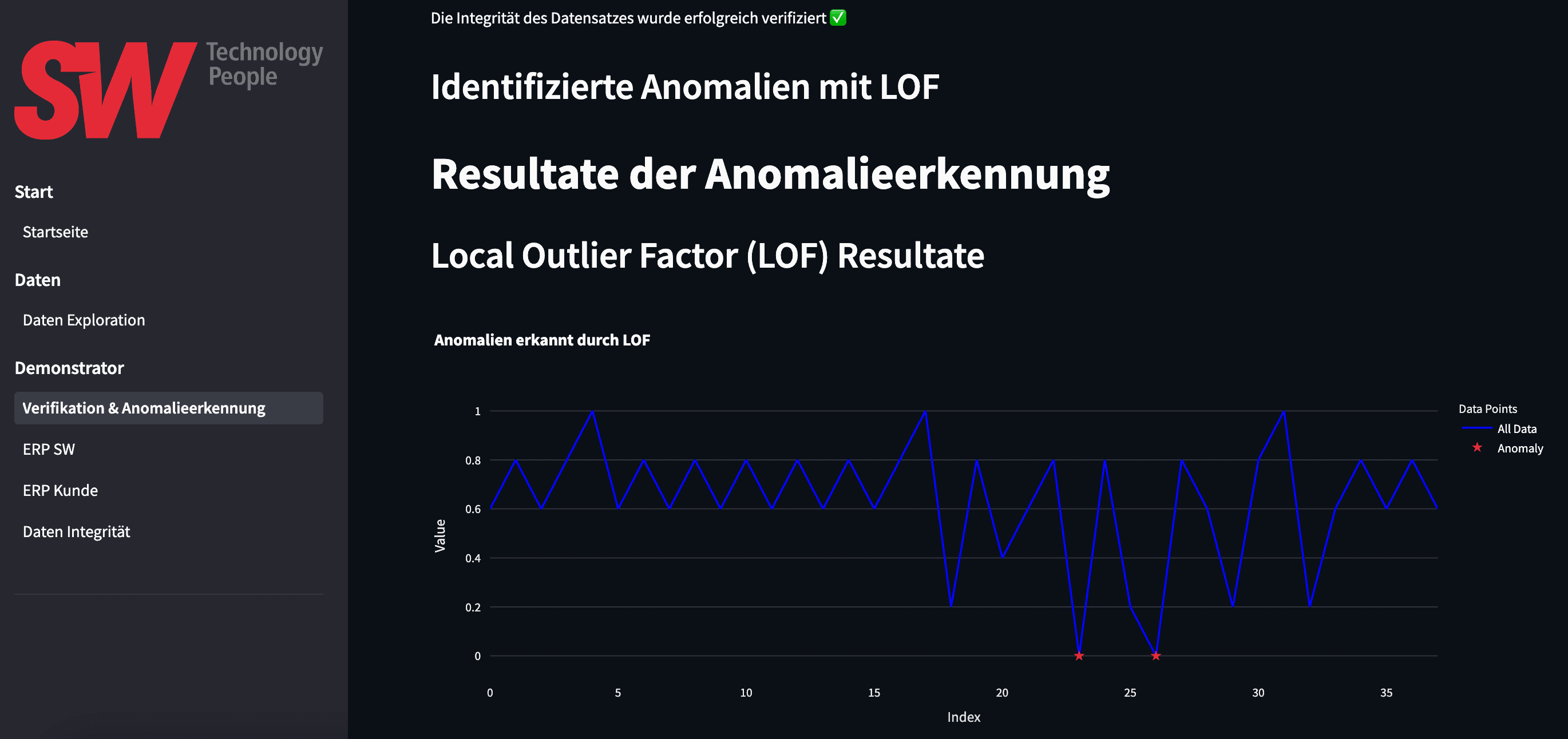
Data Integrity Log
In this demonstrator, users manually trigger the configuration and execution of the anomaly detection. In contrast, a production system would automate and continuously run these steps. The third feature is a data integrity log to give users better visibility of what is happening. This audit trail has three levels: At the top level, it shows the health status of each machine and the last verified batch used for anomaly detection.

Next, it breaks down each machine into components, displaying health statistics for each

Finally, it presents detailed logs of every anomaly detection run and whether the data integrity check succeeded.

As we wrap up this blog post series, what began as a technical experiment has evolved into something much broader. It points toward a future of industrial intelligence that values transparency and built-in trust. By embedding trust directly into machine data and equipping AI with verified information, we do more than detect anomalies. We enable machines to communicate, collaborate, and maintain themselves. Ultimately, this proof of concept is a first step toward an Industry 4.0 landscape that is autonomous, secure, and transparent, where trust is not an afterthought but a foundation.
Curious how our blockchain-based data-integrity solution can help your business? Check out our one-pager for a quick overview of its key benefits!


by Simon Zehentreiter | 19 December 2024 | AI, Blockchain, COSMIC-X, Gaia-X
In the first part of this Cosmic-X blogpost series, we evaluated various blockchain platforms for their suitability in Industry 4.0 and explained why we chose the Secret Network with its confidential computing capabilities. Today, we’ll explore how we use the Secret Network to secure machine data integrity from its origin to its consumption.
Need for Data Integrity
Securing data integrity in Industry 4.0 is crucial because systems and devices rely on accurate data to function effectively. Tampered or incorrect data can lead to poor decisions, operational failures, and vulnerabilities in key sectors like manufacturing and logistics. With IoT and AI driving Industry 4.0, maintaining data accuracy ensures reliable operations, protects sensitive information, and prevents cyber threats that disrupt businesses and critical infrastructure.
Anchoring data close to its source is essential for securing integrity across the entire data processing chain, which often involves multiple distributed systems. For machines, this means securing the data before it leaves the device. At the same time, the system must protect the anchored data from tampering after export. Blockchain’s immutable nature aligns perfectly with this paradigm. That’s why we built a Wallet Service on top of the Secret Network. This service integrates seamlessly into any machine to secure its data integrity in a decentralized and privacy-preserving manner.
Wallet Service
The Wallet Service acts as a gateway for communication with the Secret Network. It deploys onto any machine infrastructure that supports Docker. By using the Wallet Service, machines interact directly with the blockchain and its smart contracts. The service assigns each machine a unique identity through a public-private key pair. With its private key, the machine signs and broadcasts transactions to anchor its data on the Secret Network. The blockchain’s encryption ensures that no unauthorized third party can access the data. For details on how the network reaches consensus despite encryption, refer to our previous post.
Integration
To simplify integration, the Wallet Service offers a straightforward REST API with two endpoints. The ingress endpoint accepts a batch of data in a defined structure for anchoring. After receiving the data, the Wallet Service hashes it and stores the resulting hash in the service’s smart contract through a transaction on the Secret Network. This process creates an immutable fingerprint, allowing anyone to verify the integrity of a data batch through the Wallet Service’s verification endpoint. Since data verification typically occurs in systems other than the one that supplied the data, the Wallet Service supports deployment anywhere. In distributed data processing scenarios like Cosmic-X, entities that consume data instantiate a Wallet Service to verify data integrity before making decisions. For example, an AI service provider might deploy a Wallet Service in its cloud environment to verify data before using it for training or inference.
Requirements
Two conditions must be met for this workflow to function: first, the verifying Wallet Service must have the appropriate viewing key from the machine that supplied the data. Otherwise, it cannot decrypt and query the fingerprints stored in the smart contract. Second, the format and schema of the data batch must remain standardized across the processing chain. To achieve this, we developed a Data Integrity Protocol as the foundation of the Wallet Service.
Data Integrity Protocol
To anchor and verify data batches reliably, the Wallet Service requires a standardized protocol. Both the data anchoring and verification processes must adhere to a common data format, schema, and canonicalization standard. For Cosmic-X, we chose JSON as the data format and RFC 8785 as the canonicalization algorithm. Canonicalization ensures reliable cryptographic operations on JSON data by defining methods for handling whitespace, data types, and objects.
Batch Structure
Considering use case requirements and the limitations of edge and cloud environments in Cosmic-X, we define a data batch as one hour’s worth of sensor data collected from a machine. The figure below shows an extract of a data batch collected from one of the use cases. The batch includes a metadata object used only for the Wallet Service’s business logic. This metadata contains key-value pairs such as the batchId and placeholders for the payload hash and the transaction hash on the Secret Network blockchain. The payload, which the system hashes during anchoring, consists of discrete sensor measurements. Each measurement uses a composite key created by concatenating the variable name with the Unix timestamp of its recording. The measurements include key-value pairs for variable name, timestamp, absolute value, and data type.

The batchId is the most critical part of a data batch. Since the Wallet Service uses it to anchor and later locate the data batch for verification, the batchId must be unique. In this setup, the batchId combines a machine ID with a Unix timestamp representing the time range of measurements in the batch, rounded to the nearest hour. For example, if machine 2080839 collects measurements from 11:01:23 to 11:59:43 on May 16, 2024, the batchId becomes 2080839_1715853600.
In the next post, we’ll showcase how we integrated the Wallet Service with three live machines and an AI service to enable secure and accurate anomaly detection in machine components.
Curious how our blockchain-based data-integrity solution can help your business? Check out our one-pager for a quick overview of its key benefits!

by Rebecca Johnson | 4 December 2024 | Blockchain, Track and Trust
This article is the sixth and final article in a series about our probabilistic 360° supply chain tracking product, Track & Trust. Our previous articles described how the system works. Now, we dive into the results of our pilot operations. TLDR – We successfully tracked all the goods to their final delivery locations despite serious challenges!
The Track & Trust Mission in Southern Lebanon

We chose to track shipments of solar equipment for the Track & Trust Pilot. Destined for clinics and schools serving refugees in Beqaa Valley, Lebanon, these shipments were critical to the region. The area is home to over 300,000 Syrian refugees, according to UNHCR, and they all need medical care. Our partners, Aid Pioneers, Multi Aid Programs, and Al-Manhaj, collaborate to provide logistics, education, and medical care on the ground.
The clinics and schools require continuous a continuous electrical power supply. Due to Lebanon’s severe energy crisis, the public grid provides only about two hours of electricity per day, making the delivery of efficient healthcare services an immense challenge. In absence of a stable grid, most of the region’s essential services rely on generators, leaving the financial stability of operations at the whim of the ever-increasing price of diesel. Typical health clinics have thousands of dollars in monthly operating costs due to the need to purchase this fuel. To address this, Aid Pioneers is replacing diesel power systems with clean, abundant solar energy, one clinic at a time. By reliably shipping the equipment from Tripoli to Beqaa Valley, they achieve this goal with our help. Specifically the shipments we’ve tracked during the pilot contained all the equipment needed to outfit two clinics with enough solar power to cover all their needs. Aid Pioneers partner, Multi Aid Programs runs the clinics which received the solar and medical equipment we tracked.
Tracking Impact

Using Track & Trust, Aid Pioneers and their partners gained a clear view of what was happening to the parts in their shipment. As a result, they avoided extra trips, saving work and potential exposure to danger. Our team planned this deployment long before the recent conflict broke out, and our system performed well in the midst of a very difficult situation. Effective management of the challenges that arose was crucial to the success of the project.
During the shipments, ground personnel encountered outages of critical infrastructure, losing power and 4G connectivity several times. Fortunately, our Track & Trust mesh node infrastructure filled the gap, and our battery backup system enabled the system to run despite the power grid being down. The system’s design allowed it to handle such outages.

When 4G connectivity was lost, our mesh nodes cached delivery data until it could be passed between nodes. Utilizing technologies developed with our partner, Weaver Labs, we ensured the data was secure. Next, we used a satellite-enabled mesh node to post data that would have otherwise been lost via Iridium satellite uplink, developed by our partner Ororatech.
Aid Pioneers received hundreds of updates about the status of the goods from us. To ensure the integrity of the data, we cryptographically signed and anchored these updates to the ASI Alliance blockchain, making them highly trustworthy. This extra step was crucial to the project’s success. Together the result is highly trustable probabilistic 360° supply chain tracking.
Energy Independence One Clinic at a Time

Two major sets of shipments were completed under the watchful eye of Track & Trust, and a third set is currently being shipped to Lebanon. With 110 kWp of power, the solar systems make two entire clinics energy independent for the next twenty years. Additionally, we tracked a container of medical goods, which Al-Manhaj and Multi Aid Programs are using to save lives and provide medical treatment in Tripoli and the Beqaa Valley.
Track & Trust Proof of Resilience
The design of Track & Trust allows it to work in various contexts, providing resilience and probabilistic 360° supply chain tracking. Adaptable to different scenarios, our system is highly versatile. As we continue to develop and refine our system, we will meet the changing needs of our partners.
Next Steps
Following this piloting success, we will examine plans to make the system more user-friendly. Logistics organizations that could use more resilience in their field operations are also being contacted. If this series of blog posts has piqued your interest, please reach out, and we will schedule a call or demo.
<<< Previous Post

by Rebecca Johnson | 12 November 2024 | Blockchain
This article is the fifth in a series of posts about how our probabilistic 360° supply chain tracking product, Track & Trust, works. We described how the system works at a component level in our previous articles. Now, we dive into the challenging environment where our pilot operations have been executed. We selected Lebanon, one of the most difficult operational locations in the world, for our first pilot shipments to really prove the mettle of the system.

Aid Pioneers – an Ideal Pilot Partner
We have been working with our humanitarian partner Aid Pioneers for many months to prepare for these shipments. Aid Pioneers connects available resources from donors directly to recipient organizations. Through close collaboration with on the ground initiatives and the private sector, Aid Pioneers connects resources from donors directly with local organizations to foster sustainable, community-led change. They do this in places that need them most, making them a highly innovative humanitarian agency. They take an end-to-end approach to the supply chain, which we believe suits Track & Trust perfectly. Aid Pioneers needs to extend tracking of supplies beyond what typical supply chain tracking products can accomplish. We are helping them achieve this.

Supply Chain Tracking Challenges
Aid Pioneers‘ logistics environment provides a perfect showcase for what Track & Trust can do. When Aid Pioneers ships a container full of medical supplies or solar power generation equipment to a Lebanese clinic or school, they hire a freight forwarder to pick up the goods. The freight forwarder then organizes the delivery to a local port via semi-truck. After that, a freight forwarder loads the container onto a ship. The ship travels to a port of entry in Lebanon, and we track its progress using a typical tracking link. However, once the container clears customs, we take over. We actively track it and pick up where traditional systems stop working.

At this point we encounter tricky conditions. Aid Pioneers local lebanese partner Al-Manhaj breaks down containers into multiple pallets or depalletizes them. They do this before final delivery. After that they deliver goods to one location while others go to other locations at different times. To keep track of what was delivered when, we use probabilistic 360° supply chain tracking. We also developed strategies to deal with power and connectivity outages.
Outwitting Outages
These outages always happen at the wrong time so it’s important that the system is able to handle them. We do this with built in backup batteries and a battery management system. On top of that, the communications landscape is very challenging. Sometimes there’s 4G connectivity and at other times there’s outages. Our mesh nodes can operate no matter, though, by caching incoming data locally. The nodes just wait until the data can be posted or handed off to other mesh nodes. This approach multiplies the effectiveness of our communications assets. On top of that, we positioned one of our satellite uplinks at a local school. As a result, every event is (at the minimum) recorded and transmitted asynchronously – even when conditions are at their worst.
These logistics challenges are not unique to Aid Pioneers’ operations. However, they are particularly pronounced in the places where they work. We believe that if our system works there and brings value to freight forwarders and humanitarian organizations, it will work anywhere. As a result of this testing we’re confident in the capabilities of Track & Trust.
In our next post we’ll describe exactly how the our pilot operations went – and what the big value drivers are.
<<Previous Post
Next Post>>

by Simon Zehentreiter | 8 November 2024 | AI, Blockchain, COSMIC-X, Gaia-X
With the Cosmic-X project nearing its conclusion, it is finally time to lift the curtain on the blockchain solution that Datarella has built over the last two years to enable confidential computing and data sharing in Industry 4.0. In this first entry of a series of technical posts about designing, implementing, and integrating an edge-to-cloud blockchain solution, we discuss the evaluation process for selecting a suitable blockchain platform for Cosmic-X and how that platform operates on a protocol level to provide an open, transparent, and secure infrastructure for industrial use cases.
Evaluating Blockchain Platforms
Today, many different blockchain platforms exist, but their suitability for industrial use cases remains specific or, at times, limited. To achieve the best match between the requirements of Cosmic-X and the possibilities of blockchain technologies, the team conducted an extensive evaluation process. This evaluation compared both private and public blockchain platforms based on security, privacy, scalability, and interoperability.
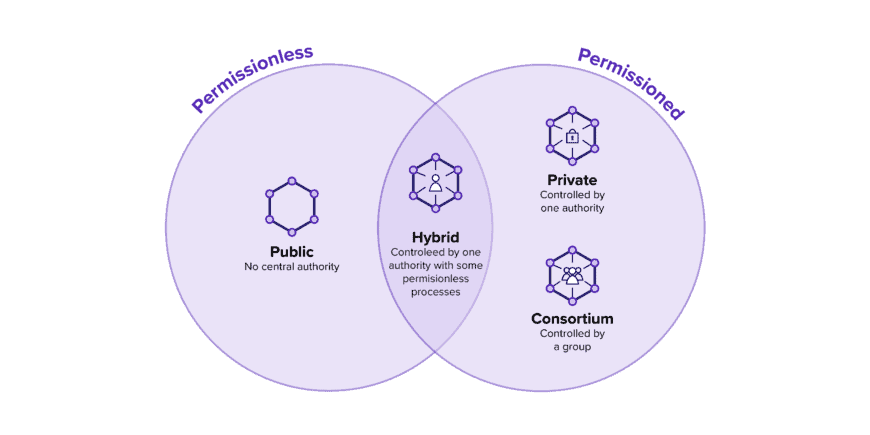
Current-generation blockchain platforms predominantly perform well in security and scalability, yet privacy and interoperability often fall short. To achieve privacy in industrial scenarios like Cosmic-X, organizations have almost exclusively used private or consortium blockchains such as Hyperledger Fabric in the past. However, these approaches inherently involve high infrastructure costs for the operating parties, as well as centralization and limited interoperability. In contrast, public blockchains offer resilience, cost efficiency, and a degree of interoperability. Though only recently have they started focusing on privacy and data protection. Blockchain protocols with confidential computing capabilities remain relatively new and untested. Nevertheless, when weighing the advantages and disadvantages of the two approaches, a privacy-focused public network emerges as the preferred solution in an industrial context.
For a public network to meet Cosmic-X’s privacy and data protection requirements, it must support the multi-tenancy paradigm. Multi-tenancy enables a single instance of a software application to serve multiple clients while ensuring logical isolation. Different clients share an underlying infrastructure, which optimizes resource use and reduces infrastructure costs. Further, it enhances efficiency in data access, management, and collaborative data sharing.

Through this evaluation, the Cosmos-based Secret Network emerged as the blockchain platform best suited for Cosmic-X. The Secret Network functions as a public blockchain specifically developed for confidential computing. By combining established encryption techniques with trusted execution environments, it provides so-called Secret Contracts. This type of smart contract establishes consensus on computation without disclosing incoming or outgoing data. Integrated access control mechanisms enable third-party access and create an auditable processing chain. Thus, the Secret Network satisfies the need for multi-tenancy capability while retaining all the benefits of a public network.
How the Secret Network Works
The Secret Network leverages Intel Software Guard Extensions (Intel SGX) to create Trusted Execution Environments (TEE) that enable Secret Contracts. These smart contracts, based on the CosmWasm framework, allow for fully private computation of data. Outside a TEE, the transaction payloads and the network’s current state are encrypted at all times. Only the data owner and an authorized third party can decrypt and view data inputs and outputs. A combination of symmetric and asymmetric encryption schemes—ECDH (x25519), HKDF-SHA256, and AES-128-SIV—achieves this end-to-end encryption. Each validator in the network must run an Intel SGX-compatible CPU and instantiate a TEE that follows the network’s rules.
When an encrypted transaction arrives in the shared mempool of the network, a validator forwards it to their TEE, where a shared secret is derived and used to decrypt the transaction. The WASMI runtime then processes the plaintext input. Finally, the validator re-encrypts the updated contract state and broadcasts it to the network through a block proposal. If over two-thirds of the current network voting power agree on the result, the network appends the proposed block to the Secret Network blockchain.
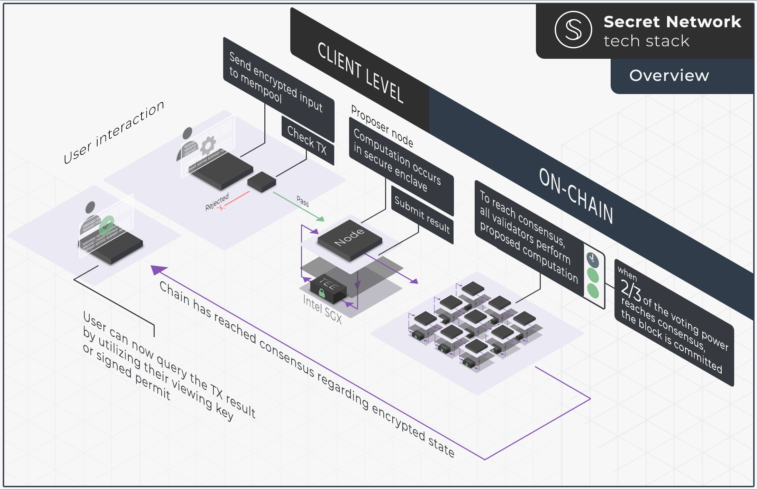
For access control, the Secret Network offers Viewing Keys and Permits. A Viewing Key acts as an encrypted password that grants a third party permanent access to data related to a specific smart contract and private key. A Permit allows a more granular approach, restricting viewing access to specific parts of data for a set period. Consequently, despite its encrypted nature, the network remains fully auditable.
In the next post, we’ll explore how we leverage the Secret Network to secure machine data integrity directly from its point of origin to its consumption by a Machine Learning Model.

by Rebecca Johnson | 21 October 2024 | Blockchain, Track and Trust
This is the fourth article in a series of technical posts about how Track & Trust works at a component level. To begin with, we’ll outline how our orchestration systems, real-time monitoring, and dashboards work together. Additionally, we’ll explore the challenges we faced and how we overcame them. Quick navigation links to follow-up articles will be provided at the bottom of each article once the series is complete.
Orchestration Systems and CI/CD
To manage a large fleet of custom-built mesh node devices, we needed to develop advanced orchestration systems. Specifically, these systems enable us to provision and manage devices efficiently. Furthermore, we created a special approach to real-time monitoring of node health in the field. As a result, Track & Trust includes a full suite of dashboards that we can now use to monitor key performance indicators and display the outputs of our Probabilistic 360° Supply Chain Tracking product. In addition the orchestration systems we built are now fully operational and enable a highly flexible approach to updating and managing the software deployed to our hardware in the field. Let’s jump into how we accomplished this feat.
The Addressing Challenge

Most people aren’t aware of this but devices on 4g connections don’t have static IP addresses. The IP addresses are assigned by the constantly shifting cellular towers the mobile device connects to. This is a real problem if you want to set up a software pipeline to trigger updates on mobile or iOT devices. In order to solve this we set up a virtual private network (VPN). This VPN is based on the open source wireguard protocol. Basically it’s a software defined network with tailscale under the hood. This approach means using a peer-to-peer mesh network to handle addressing devices inside our mesh network (pretty meta huh?). By routing our network traffic through a VPN we achieved much better security. On top of this we got static virtual addresses. This allowed us to name and manage the machines at the network level.
Push or Pull Orchestration Systems?
With the addressing problem solved another challenge popped up. If the machines are only online intermittently, a push approach to updates becomes impossible. This is because when you push the updates it might not reach all the machines. Some machines will inevitably be offline. The solution to this issue was to use a scheduled automation to automatically pull updates from an ansible automation engine. This, in turn, is controlled by a continuous integration and deployment system based around Semaphore. This enabled us to write code in an integrated development environment, push it to gitlab, and then trigger a build that the machines pick up. These builds, then deploy automatically on a daily basis whenever the machines happen to come online.
 While we were still heavily in development, having this pipeline in place vastly increased our efficiency. We were able to write code and deploy to our custom made IoT hardware basically as though it was sitting in a cloud environment. On top of this we were able to designate groups of machines as dev machines and others as stage or prod machines. This combination allowed us to develop and test both hardware and software independently of production and staging environments. It empowered us to rapidly iterate on the status quo without breaking hardware already in use in the field. Additionally the moment that we were ready to update mesh nodes in the field, we could earmark them to update themselves with well tested code the next time they came online.
While we were still heavily in development, having this pipeline in place vastly increased our efficiency. We were able to write code and deploy to our custom made IoT hardware basically as though it was sitting in a cloud environment. On top of this we were able to designate groups of machines as dev machines and others as stage or prod machines. This combination allowed us to develop and test both hardware and software independently of production and staging environments. It empowered us to rapidly iterate on the status quo without breaking hardware already in use in the field. Additionally the moment that we were ready to update mesh nodes in the field, we could earmark them to update themselves with well tested code the next time they came online.
Real-Time Monitoring

We needed advanced monitoring to easily update our software fleet. To achieve this, we set up an end-to-end observability pipeline using Fluentbit. This pipeline routed data in real-time from our mesh nodes into a database. Subsequently, we displayed real-time data in Grafana for management purposes. This approach enabled us to debug faster without having to SSH into a specific node to get its logs.

Finally, our Grafana dashboards showed us if all services were up and running, as well as key indicators of device health such as memory usage, temperature, and battery life. We could display logs in the timeframes we were interested in for the machine groups we wanted to monitor. In conclusion, this monitoring technology gave us valuable insights into ensuring our deployed hardware was working correctly and allowed us to fix issues quickly.

The Track & Trust dashboard with realtime information about each machine to optimize field operations
<<Previous Post
Next Post>>