Wired bringt eine schönen Abriss der Geburtsstunde von Big Data, die grundsätzlich mit der Entwicklung und dem Einsatz von Hadoop gleichzusetzen ist. Das Software System, das heute von allen grossen Networks wie Facebook, Twitter, Yahoo etc. eingesetzt wird, wurde 2006 von Doug Cutting und Michael Cafarella programmiert. Pate stand Google, die bereits im Jahr 2004 den Grundstein legten und ihre Architektur open source zur Verfügung stellten.
Mit dem aus dem Datenspeicher Hadoop Distributed File System HDFS und der Datenverarbeitungsplattform MapReduce besteht, können riesige Datenmengen gespeichert und in einem zweiten Schritt über hunderte oder gar tausende Server ausgeliefert werden. Über MapReduce werden dann grosse Rechenaufgaben in viele kleine Aufgaben verteilt über mehrere Serververbünden (Cluster) aufgeteilt. Diese Architektur machte zum ersten Mal die Verarbeitung grosser Datenmengen zu vertretbaren Kosten möglich: anstelle mehrerer Supercomputer können handelsübliche Server eingesetzt werden.
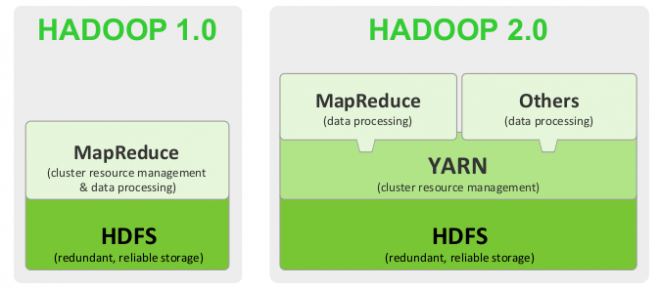
Mit der Zeit wurde der Ruf nach einer Möglichkeit lauter, Daten direkt aus Clustern zu ziehen, ohne über MapReduce gehen zu müssen. Workarounds wie Pig, Hove, Twitters Storm oder Yahoos Spark ermöglichen dies – allerdings kommen auch sie nicht gänzlich ohne MapReduce aus. In der neuen Version von Hadoop – Hadoop 2.0 – wird genau dieses Problem gelöst: über die neue Systemkomponente YARN können Entwickler Applikationen direkt mit HDFS kommunizieren lassen, ohne MapReduce zu bemühen.
YARN befindet sich aktuell in der Alpha-Version und ist schon in einigen Hadoop- Auslieferungen eingebaut, wie beispielsweise in Cloudera. Eine Beta-Version ist bereits angekündigt.
Featured Image: Hortonworks